You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Проблемы при генерации NFT
- Thread starter Admin
- Start date
Василий Чехов
Holder
- WMBTC
- 0
IPFS — мощная система хранения файлов, но не без ограничений. В последние месяцы многие люди и проекты начали хранить папки с тысячами (иногда десятками тысяч) файлов. При попытке просмотреть содержимое этих папок через шлюз они не понимают, почему содержимое не загружается.
Простой ответ: шлюзы IPFS не имеют встроенной нумерации страниц. Это означает, что когда вы пытаетесь просмотреть папку, содержащую, скажем, 10 000 файлов, шлюз и браузер пытаются загрузить все эти файлы одновременно. Как вы можете себе представить, это может быть непосильным для браузера.
Как это исправить?
Ну, ты не можешь. Но вы можете обойти это. Каждый из файлов в вашей папке по-прежнему доступен, поэтому вы должны использовать ссылку на каталог вашей папки с именем файла, добавленным в конце. Допустим, CID вашей папки "MY_FOLDER_CID". Допустим, у вас есть файл с именем «1.json». Вы загрузите этот файл, перейдя по ссылке:
GATEWAY_URL/ipfs/MY_FOLDER_CID/1.json
Это по-прежнему адресуемый по содержимому способ доступа к файлам в папках в IPFS. Если содержимое папки когда-либо изменится, изменится CID папки и, следовательно, изменится путь к файлу. У вас есть те же гарантии проверяемости с этим методом.
Что делать, если мне нужны CID внутри папки?
Чтобы получить все CID дочерних файлов, вам потребуется запустить собственный локальный узел IPFS. Вам нужно будет добавить папку на ваш узел IPFS, а затем запустить следующую команду из командной строки:
ipfs dag get <FOLDER CID>
Простой ответ: шлюзы IPFS не имеют встроенной нумерации страниц. Это означает, что когда вы пытаетесь просмотреть папку, содержащую, скажем, 10 000 файлов, шлюз и браузер пытаются загрузить все эти файлы одновременно. Как вы можете себе представить, это может быть непосильным для браузера.
Как это исправить?
Ну, ты не можешь. Но вы можете обойти это. Каждый из файлов в вашей папке по-прежнему доступен, поэтому вы должны использовать ссылку на каталог вашей папки с именем файла, добавленным в конце. Допустим, CID вашей папки "MY_FOLDER_CID". Допустим, у вас есть файл с именем «1.json». Вы загрузите этот файл, перейдя по ссылке:
GATEWAY_URL/ipfs/MY_FOLDER_CID/1.json
Это по-прежнему адресуемый по содержимому способ доступа к файлам в папках в IPFS. Если содержимое папки когда-либо изменится, изменится CID папки и, следовательно, изменится путь к файлу. У вас есть те же гарантии проверяемости с этим методом.
Что делать, если мне нужны CID внутри папки?
Чтобы получить все CID дочерних файлов, вам потребуется запустить собственный локальный узел IPFS. Вам нужно будет добавить папку на ваш узел IPFS, а затем запустить следующую команду из командной строки:
ipfs dag get <FOLDER CID>
Василий Чехов
Holder
- WMBTC
- 0
IPFS is a powerful file storage system, but it is not without its limitations. In recent months, many individuals and projects have begun storing folders with thousands (sometimes tens of thousands) of files in them. When trying to view the contents of these folders through a gateway, they are confused about why the content won't load.
The simple answer is IPFS Gateways do not have built-in pagination. This means when you try to view a folder with, say, 10,000 files in it, the gateway and the browser are trying to load all of those files at once. As you can imagine, this can be overwhelming for a browser.
How do you fix it?
Well, you can't. But you can get around it. Every one of the files within your folder is still accessible, so you should use the link to your folder directory with the filename appended at the end. Let's say your folder CID is "MY_FOLDER_CID". And let's say you have a file named "1.json". You would load that file by going to:
GATEWAY_URL/ipfs/MY_FOLDER_CID/1.json
This is still a content addressable way to access files within folders on IPFS. If the contents of the folder ever change, the folder CID would change and thus the path to the file would change. You have the same verifiability assurances with this method.
What If I Need The CIDs Inside The Folder?
In order to get all of the child file CIDs, you're going to need to be running your own local IPFS node. You will need to add the folder to your IPFS node and then run the following command from the command line:
ipfs dag get <FOLDER CID>
The simple answer is IPFS Gateways do not have built-in pagination. This means when you try to view a folder with, say, 10,000 files in it, the gateway and the browser are trying to load all of those files at once. As you can imagine, this can be overwhelming for a browser.
How do you fix it?
Well, you can't. But you can get around it. Every one of the files within your folder is still accessible, so you should use the link to your folder directory with the filename appended at the end. Let's say your folder CID is "MY_FOLDER_CID". And let's say you have a file named "1.json". You would load that file by going to:
GATEWAY_URL/ipfs/MY_FOLDER_CID/1.json
This is still a content addressable way to access files within folders on IPFS. If the contents of the folder ever change, the folder CID would change and thus the path to the file would change. You have the same verifiability assurances with this method.
What If I Need The CIDs Inside The Folder?
In order to get all of the child file CIDs, you're going to need to be running your own local IPFS node. You will need to add the folder to your IPFS node and then run the following command from the command line:
ipfs dag get <FOLDER CID>
ArteMazunin
Newbie
- WMBTC
- 0
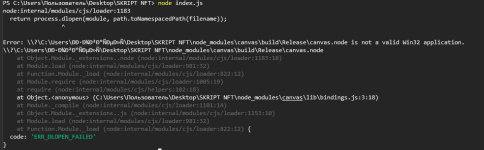
Привет.Есть ошибка при node index.js
Сможете помочь?

Сможете помочь?
Василий Чехов
Holder
- WMBTC
- 0
Ждите, скоро выйдет видео от Валентина.
You haven't joined any rooms.